
Abstract
Open Science is an umbrella term encompassing a multitude of assumptions about the future of knowledge creation and dissemination. Based on a literature review, this chapter aims at structuring the overall discourse by proposing five Open Science schools of thought: The infrastructure school (which is concerned with the technological architecture), the public school (which is concerned with the accessibility of knowledge creation), the "measurement school"(which is concerned with alternative impact measurement), the "democratic school"(which is concerned with access to knowledge) and the "pragmatic school" (which is concerned with collaborative research).
There is scarcely a scientist who has not stumbled upon the term ‘Open Science’ of late and there is hardly a scientific conference where the word and its meaning are not discussed in some form or other. ‘Open Science’ is one of the buzzwords of the scientific community. Moreover, it is accompanied by a vivid discourse that apparently encompasses any kind of change in relation to the future of scientific knowledge creation and dissemination; a discourse whose lowest common denominator is perhaps that science in the near future somehow needs to open up more. In fact, the very same term evokes quite different understandings and opens a multitude of battlefields, ranging from the democratic right to access publicly funded knowledge (e.g. open access to publications) or the demand for a better bridging of the divide between research and society (e.g. citizen science) to the development of freely available tools for collaboration (e.g. social media platforms for scientists). From this vantage point, openness could refer to pretty much anything: The process of knowledge creation, its result, the researching individual him- or herself, or the relationship between research and the rest of society.
The diversity, and perhaps ambiguity, of the discourse is, however, understandable considering the diversity of stakeholders that are directly affected by a changing scientific environment. These are in the first place: Researchers from all fields, policy makers, platform programmers and operators, publishers, and the interested public. It appears that each peer group discussing the term has a different understanding of the meaning and application of Open Science. As such the whole discourse can come across as somewhat confusing. By structuring the Open Science discourse on the basis of existing literature, we would like to offer an overview of the multiple directions of development of this still young discourse, its main arguments, and common catchphrases. Furthermore, we intend to indicate issues that in our eyes still require closer attention.
Looking at the relevant literature on Open Science, one can in fact recognize iterative motives and patterns of argumentation that, in our opinion, form more or less distinct streams. Referring to the diversity of these streams, we allowed ourselves to call them schools of thought. After dutifully combing through the literature on Open Science, we identified five distinct schools of thought. We do not claim a consistently clear-cut distinction between these schools (in fact some share certain ontological principles). We do, however, believe that our compilation can give a comprehensible overview of the predominant thought patterns in the current Open Science discourse and point towards new directions in research regarding Open Science. In terms of a literature review, we furthermore hope that this chapter identifies some of the leading scholars and thinkers within the five schools.
The following table (table 1) comprises the five identified schools together with their central assumptions, the involved stakeholder groups, their aims, and the tools and methods used to achieve and promote these aims.
| School of thought | Central assumption | Involved groups | Central Aim | Tools & Methods |
| Democratic | The access to knowledge is unequally distributed. | Scientists, polititians, citizens | Making knowledge freely available for everyone. | Open access, intellectual property rights, Open data, Open code |
| Pragmatic | Knowledge-creation could be more efficient if scientists worked together. | Scientists | Opening up the process of knowledge creation. | Wisdom of the crowds, network effects, Open Data, Open Code |
| Infrastructure | Efficient research depends on the available tools and applications. | Scientists & platform providers | Creating openly available platforms, tools and services for scientists. | Collaboration platforms and tools |
| Public | Science needs to be made accessible to the public. | Scientists & citizens | Making science accessible for citizens. | Citizen Science, Science PR, Science Blogging |
| Measurement | Scientific contributions today need alternative impact measurements. | Scientists & politicians | Developing an alternative metric system for scientific impact. | Altmetrics, peer review, citation, impact factors |
It must be noted that our review is not solely built upon traditional scholarly publications but, due to the nature of the topic, also includes scientific blogs and newspaper articles. It is our aim in this chapter to present a concise picture of the ongoing discussion rather than a complete list of peer-reviewed articles on the topic. In the following, we will describe the five schools in more detail and provide references to relevant literature for each.
Public School: The Obligation to Make Science Accessible to the Public
In a nutshell, advocates of the public school argue that science needs to be accessible for a wider audience. The basic assumption herein is that the social web and Web 2.0 technologies allow scientists, on the one hand, to open up the research process and, on the other, to prepare the product of their research for interested non-experts (see table 2).
Accordingly, we recognize two different streams within the public school: The first is concerned with the accessibility of the research process (the production), the second with the comprehensibility of the research result (the product). Both streams involve the relationship between scientists and the public and define openness as a form of devotion to a wider audience. In the following section we will elaborate more on both streams in reference to relevant literature.
| Author (Year) Type of Publication | Title | Content |
| Puschmann (2012) Book chapter | (Micro)blogging Science? Notes on Potentials and Constraints of New Forms of Scholarly Communication | Scientists today need to make their research accessible to a wider audience by using (micro)blogs. “Scientists must be able to explain what they do to a broader public to garner political support and funding for endeavors whose outcomes are unclear at best and dangerous at worst, a difficulty that is magnified by the complexity of scientific issues.” (P. XX) |
| Cribb & Sari (2010) Monograph | Open Science - Sharing Knowledge in the digital age | The accessibility of scientific knowledge is a matter of its presentation. “Science is by nature complicated, making it all the more important that good science writing should be simple, clean and clear.” (p. 15) |
| Grand et al (2012) Journal Article | Open Science: A New “Trust Technology”? | Scientists can raise public trust by using web 2.0 tools “As mainstream science—and comment on science— follows the pioneers into the realm of Web 2.0, to be able to navigate the currents of the information flow in this relatively unmapped territory, scientists and members of the public will all need reliable and robust tools.” (p. 685) |
| Morris & Mietchen (2010) Proceedings | Collaborative Structuring of Knowledge by Experts and the Public | Using web 2.0 tools to make knowledge production accessible for the public. “(…) there is still plenty of opportunities for reinventing and experimenting with new ways to render and collaborate on knowledge production and to see if we can build a more stable, sustainable and collegial atmosphere (…) for experts and the public to work together.” (p. 32) |
| Tacke (2012) Blog entry | Raus aus dem Elfenbeinturm: Open Science. | The Web 2.0 gives scientists new opportunities to spread scientific knowledge to a wider public. “Im einfachsten Fall können Wissenschaftler etwa in Blogs über Themen aus ihrem Fachgebiet berichten und Fragen von interessierten dazu beantworten.” (p. 2) |
| Irwin (2006) Monograph | The politics of talk | Due to modern technology, citizens can participate in scientific knowledge creation. “(…) this book is committed both to an improved understanding of ‘science, technology and citizenship’ and to better social practice in this area (…)” (p. 8) |
| Hand (2010) Article | Citizen science: People power | Citizens possess valuable knowledge from which science can benefit. “By harnessing human brains for problem solving, Foldit takes BOINC’s distributed-computing concept to a whole new level.” (p. 2) |
| Ebner & Maurer (2009) Article | Can microblogs and weblogs change traditional scientific writing? | Blogs can contribute to make research more accessible to the public. Yet they cannot replace articles and essays in scholarly communication. “Weblogs and microblogs can enhance lectures by bringing the resources of the WorldWideWeb to the course and making them discussable. Both new technologies, however, cannot replace writing essays and articles, because of their different nature.” |
| Catlin-Groves (2012) Review article | The Citizen Science Landscape: From Volunteers to Citizen Sensors and Beyond | Citizens can help monitoring on a large scale. “The areas in which it [citizen science] has, and most probably will continue to have, the greatest impact and potential are that of monitoring ecology or biodiversity at large geographic scales” |
| Powell & Colin (2009) Article | Participatory paradoxes: Facilitating citizen engagement in science and technology from the Top-Down? | Citizen science projects are often short-lived “Most participatory exercises do not engage citizens beyond an event or a few weeks/months, and they do not build citizens’ participatory skills in ways that would help them engage with scientists or policy makers independently.” (p. 327) |
Accessibility to the Research Process — Can Anyone be a Scientist?
To view the issue as a formerly hidden research process becoming transparent and accessible to the common man seems a decidedly romantic image of doing science. Yet, coming from the assumptions that communication technology not only allows the constant documentation of research, but also the inclusion of dispersed external individuals (as supposed in the pragmatic school), an obvious inference is that the formerly excluded public can now play a more active role in research. A pervasive catchphrase in this relationship is the concept of so-called citizen science which, put simply, describes the participation of non-scientists and amateurs in research. Admittedly, the term, as well as the idea, have already existed for a long time. In 1978, well before the digital age, the biochemist Erwin Chargaff already used this term to espouse a form of science that is dominated by dedicated amateurs.‘’’’The meaning of the term has not changed; it merely experiences a new magnitude in the light of modern communication technology.
Hand (2010) refers, for instance, to Rosetta@Home, a distributed-computing project in which volunteer users provide their computing power (while it is not in use) to virtually fold proteins. The necessary software for this also allowed users to watch how their computer tugged and twisted the protein in search of a suitable configuration (ibid., p.2). By observing this, numerous users came up with suggestions to speed up the otherwise slow process. Reacting to the unexpected user involvement, the research team applied a new interface to the program that allowed users to assist in the folding in form of an online game called Foldit. Hand states: “By harnessing human brains for problem solving, Foldit takes BOINC’s distributed-computing concept to a whole new level” (ibid., p. 2). In this specific case, the inclusion of citizens leads to a faster research process on a large public scale. Citizen science is in this regard a promising tool to ‘harness’ a volunteer workforce. However, one can arguably question the actual quality of the influence of amateurs upon the analytical part of the research research. Catlin-Groves (2012) takes the same line as the Rosetta@Home project. She expects citizen science’s greatest potential in the monitoring of ecology or biodiversity at a large scale (ibid., p. 2). The specific fields possibly issue from the author’s area of research (Natural Sciences) and the journal in which the review article was published (International Journal of Zoology). Nonetheless, in respect to the two fields, it becomes apparent that citizens can rather be considered a mass volunteer workforce instead of actual scientists.
Indeed, most citizen science projects follow a top-down logic in which professional scientists give impetuses, take on leading roles in the process and analysis, and use amateurs not as partners, but rather as a free workforce. Irwin (2006) even claims that most citizen science projects are not likely to provide amateurs with the skills and capacities to significantly affect research in meaningful ways. Powell and Colin (2009) also criticize the lack of a meaningful impact for non-experts in the research: “Most participatory exercises do not engage citizens beyond an event or a few weeks/months, and they do not build citizens’ participatory skills in ways that would help them engage with scientists or policy makers independently” (ibid., p. 327).
The authors further present their own citizen science project, the Nanoscale Science & Engineering Center (NSEC), which at first also started as a onetime event. After the project was finished, however, the University engaged a citizen scientist group which is in frequent dialogue with field experts. The authors do not lay out in detail how citizens can actually influence research policies, rather present a perspective for a bottom-up relationship between interested amateurs and professionals. There is still a lack of research when it comes to models of active involvement of citizens in the research process beyond feeder services. Future research could therefore focus on new areas of citizen participation (e.g. citizen science in ‘soft sciences’) or alternative organizational models for citizen science (e.g. how much top-down organization is necessary?).
Another, also yet to explored, aspect that can be associated with citizen science is the crowdfunding of science. Crowdfunding is a financing principle that is already well established in the creative industries. Via online platforms, single Internet users can contribute money to project proposals of their choice and, if the project receives enough funding, enable their realization. Contributions are often rewarded with non-monetary benefits for the benefactors. A similar model is conceivable for science: The public finances research proposals directly through monetary contributions and in return receives a benefit of some description (for instance: access to the results). Crowdfunding of science allows direct public influence on the very outskirts of the research (a kind of civic scientific agenda setting) yet hardly at all during the process. Nonetheless, it possibly constitutes a new decisive force in the pursuit of research interests besides the “classica” of institutional and private funding. There is still, at least to the authors’ knowledge, no research regarding this topic. Future research could for instance cover factors of success for project pitches or the actual potential of crowdfunding for science.
Comprehensibility of the Research Result—Making Science Understandable
The second stream of the public school refers to the comprehensibility of science for a wider audience, that is mainly science communication. Whereas, for instance, citizen science concerns the public influence on the research, this sub-stream concerns the scientists’ obligation to make research understandable for a wider audience—a demand that Tacke (2011), in an entry on his blog, provocatively entitled “Come out of the ivory tower!”.
In this regard, Cribb and Sari demand a change in the scientific writing style: “Science is by nature complicated, making it all the more important that good science writing should be simple, clean and clear” (2010, p. 15). The authors’ credo is that as the scientific audience becomes broader and the topics more specific, the academic dissemination of knowledge needs to adapt.
On a perhaps more applied level, numerous authors suggest specific tools for science communication. Puschmann and Weller (2011), for instance, describe the microblogging service Twitter as a suitable tool to direct users to, for example, relevant literature and as a source for alternative impact factors (as expressed in the measurement school). In this volume (see chapter 6: Micro(blogging) Science? Notes on Potentials and Constraints of New Forms of Scholarly Communication), Puschmann furthermore dwells on the role of the scientist today and his need to communicate: “Scientists must be able to explain what they do to a broader public to garner political support and funding for endeavors whose outcomes are unclear at best and dangerous at worst, a difficulty that is magnified by the complexity of scientific issues”. As adequate tools for the new form of scholarly public justification, the author refers to scientific blogging or Twitter during conferences. In the same line of reasoning, Grand (2012) argues that by using Web 2.0 tools and committing to public interaction, a researcher can become a public figure and honest broker of his or her information (ibid., p. 684).
While numerous researchers already focus on the new tools and formats of science communication and the audience’s expectations, there is still a need for research on the changing role of a researcher in a digital society, that is, for instance, the dealings with a new form of public pressure to justify the need for instant communication and the ability to format one’s research for the public. A tenable question is thus also if a researcher can actually meet the challenge to, on the one hand, carry out research on highly complex issues and, on the other, prepare these in easily digestible bits of information. Or is there rather an emerging market for brokers and mediators of academic knowledge? Besides, what are the dangers of preparing research results in easily digestible formats?
Democratic School: Making Research Products Available
The democratic school is concerned with the concept of access to knowledge. Unlike the public school, which promotes accessibility in terms of participation to research and its comprehensibility, advocates of the democratic school focus on the principal access to the products of research. This mostly relates to research publications and scientific data, but also to source materials, digital representations of pictorial and graphical materials, or multimedia material (as Sitek and Bertelmann describe it their chapter).
Put simply, they argue that any research product should be freely available. The reason we refer to the discourse about free access to research products as the democratic school issues from its inherent rationale that everyone should have the equal right to access knowledge, especially when it is state-funded.
In the following, we will focus on two central streams of the democratic school, namely open access to research publications and Open Data. We assume that both represent a wider set of arguments that accompanies discussion on free access to research products.
Open Data
Regarding Open Data in science, Murray-Rust (2008, p. 52) relates the meaning of the prefix ‘open’ to the common definition of open source software. In that understanding, the right of usage of scientific data does not demise to an academic journal but remains in the scientific community: “I felt strongly that data of this sort should by right belong to the community and not to the publisher and started to draw attention to the problem” (ibid., p. 54). According to Murray-Rust, it is obstructive that journals claim copyright for supporting information (often data) of an article and thereby prevent the potential reuse of the data. He argues that “(it) is important to realize that SI is almost always completely produced by the original authors and, in many cases, is a direct output from a computer. The reviewers may use the data for assessing the validity of the science in the publication but I know of no cases where an editor has required the editing of (supporting information)” (ibid., p. 53). The author endorses that text, data or meta-data can be re-used for whatever purpose without further explicit permission from a journal (see table 3). He assumes that, other than validating research, journals have no use for claiming possession over supporting information—other researchers, however, do.
| Author (Year) Type of Publication | Title | Content |
| Murray-Rust (2008) Preceedings | Open data in science | Open data depends on a change of the joournal practice regarding the witholding of supporting information. “The general realization of the value of reuse will create strong pressure for more and better data. If publishers do not gladly accept this challenge, then scientists will rapidly find other ways of publishing data, probably through institutional, departmental, national or international subject repositories. In any case the community will rapidly move to Open Data and publishers resisting this will be seen as a problem to be circumvented.” (p. 64) |
| Vision (2010) Journal Article | Open Data and the Social Contract of Scientific Publishing | Data is a commodity. The sharing of data enables benefits other researchers. “Data are a classic example of a public good, in that shared data do not diminish in value. To the contrary, shared data can serve as a benchmark that allows others to study and refine methods of analysis, and once collected, they can be creatively repurposed by many hands and in many ways, indefinitely.” (p. 330) |
| Boulton et al. (2011) Comment | Science as a public enterprise: the case for open data | Data needs to be prepared in a usable format. “Conventional peer-reviewed publications generally provide summaries of the available data, but not effective access to data in a usable format.” (p. 1634) |
| Molloy (2011) Open Access Article | The open knowledge foundation: Open data means better science | Data should be free to reuse and redsitribute without restrictions. “The definition of “open”, crystellised in the OKD, means the freedom to use, reuse, and redistribute without restrictions beyond a requirement for attribution and share-alike. Any further restrictions make an item closed knowledge.” (p. 1) |
| Auer et al. (2007) | DBpedia: A nucleus for a web of open data the semantic web | Open Data is a major challenge for computer scientists in future. “It is now almost universally acknowledged that stitching together the world’s structured information and knowledge to answer semantically rich queries is one of the key challenges of computer science, and one that is likely to have tremendous impact on the world as a whole.” (p. 1) |
| Löh & Hinze (2006) | Open Data types and open functions | The problem of supporting the modular extensibility of both data and functions in one programming language (known as expression problem) “The intended semantics is as follows: the program should behave as if the data types and functions were closed, defined in one place.” (p.1) |
| Miller et al. (2008) | Open Data Commons, A Licence for Open Data | Practicing open data is a question of appropriate licencing of data. “Instead, licenses are required that make explicit the terms under which data can be used. By explicitly granting permissions, the grantor reassures those who may wish to use their data, and takes a conscious step to increase the pool of Open Data available to the web.” (p. 1) |
According to Murray-Rust’s understanding, data should not be ‘free’ (as in free beer), but open for re-use in studies foreseen or unforeseen by the original creator. The rationale behind Open Data in science is in this case researcher-centric; it is a conjuncture that fosters meaningful data mining and aggregation of data from multiple papers. Put more simply, Open Data allows research synergies and prevents duplication in the collection of data. In this regard, Murray-Rust does not only criticize the current journal system and the withholding of supporting information but also intimates at the productive potential of Open Data. It has to be said, though, that the synergy potentials that Murray-Rust describes mostly apply to natural sciences (or at least research fields in which data is more or less standardized) or at least fields in which an intermediate research product (e.g. data) can be of productive use for others.
Similar to Murray-Rust, Molloy (2011) criticises the current journal system which, according to the author, works against the maximum dissemination of scientific data that underlies publications. She elaborates on the barriers inherent in the current journal system thus: “Barriers include inability to access data, restrictions on usage applied by publishers or data providers, and publication of data that is difficult to reuse, for example, because it is poorly annotated or ‘hidden’‘’ in unmodifiable tables like PDF documents”’’(ibid, p. 1). She suggests a dealing with data that follows the Open Knowledge Foundation’s definition of openness, meaning that the data in question should be available as a whole, at no more than a reasonable reproduction cost (preferably through download), and in a convenient and modifiable form.
Other than Murray-Rust (2008) and Molloy (2011), Vision (2010), and Boulton (2011) firstly hold the researchers liable for practicing Open Data. Vision refers to a study by Campbell et al. (2002), in which it is shown that only one quarter of scientists share their research data—even upon request. According to the study, the most common reason for denying requests was the amount of effort required for compliance. Vision presents disciplinary data repositories that are maintained by the data creators themselves as an appropriate solution to the problem. This way, scientists would only need to upload their data once instead of complying with requests. Although Vision emphasizes the necessity to minimize the submission burden for the author, he does not suggest concrete inducements for scientists to upload their data (for instance forms of community recognition or other material rewards). In an empirical study about the sharing behavior among scientists, Haeussler found out that the sharing of data is indeed closely related to a form of counter-value (Haeussler, 2011, p. 8).
Who is to blame for the fact that Open Data has not yet achieved its breakthrough despite its potential? Is it the journal system and its supporting information practice? Researchers and their reluctance to share? Missing incentive systems? Or overcomplicated data repositories? The apparent divergence regarding the impediments of Open Data demonstrates the need for further empirical research on this issue. Future studies could address the reluctance of researchers to practice Open Data, the role of journals and supporting material, or the design of an appropriate online data repository or meta-data structures for research data. The implied multitude of obstacles for practicing Open Data also illustrates that research on this issue needs to be holistic.
Open Access to Research Publication
| Author (Year) Type of Publication | Title | Content |
| Cribb & Sari (2010) Monograph | Open Science - Sharing Knowledge in the Global Century | Open access to knowledge is a tool for development. “As humanity progresses the 21st century (…) many scholars point to the emergence of a disturbing trend: the world is dividing into those with ready access to knowledge and its fruit, and those without.” (p. 3) |
| Rufai et al. (2012) Journal Article | Open Access Journals in Library and Information Science: The Story so Far. | Open access helps underdeveloped countries to bridge the gap between them and developed countries. “The sustainability of open access journals in the field of LIS is evident from the study. Countries falling in the low-income economic zones have to come on open access canvas.” (p. 225) |
| Phelps, Fox & Marincola (2012) Journal Article | Supporting the advancement of science: Open access publishing and the role of mandates | Open access increases the dissemination of a scholar’s work “Maybe one of the reasons that open access is an increasingly popular choice for society journals is that it fits well with many society missions to encourage the advancement of knowledge by providing the widest possible dissemination with no barriers to access.” (p. 3) |
| Carrol (2011) Journal Article | Why full open access matters | Open access helps overcoming the inefficiancy of traditional peer-review journals “Pricing of traditional, subscription-financed scientific journals is highly inefficient. The growth in digital technologies and in digital networks should be driving down the price of access to the scholarly journal literature, but instead prices have increased at a rate greatly in excess of inflation” (p. 1) |
| Harnad & Brody (2004) | Comparing the Impact of Open Access (OA) vs. Non-OA Articles in the Same Journals | Open access can increase the number of citations and helps skirting the high access tolls of journals. “Access is not a sufficient condition for citation, but it is a necessary one. OA dramatically increases the number of potential users of any given article by adding those users who would otherwise have been unable to access it because their institution could not afford the access-tolls of the journal in which it appeared; therefore, it stands to reason that OA can only increase both usage and impact.” |
| Harnad et al. (2004) | The Access/Impact Problem and the Green and Gold Roads to Open Access | Only 5% of journals are gold, but over 90% are already green (i.e., they have given their authors the green light to self-archive); yet only about 10-20% of articles have been self-archived. “Along with the substantial recent rise in OA consciousness worldwide, there has also been an unfortunate tendency to equate OA exclusively with OA journal publishing (i.e., the golden road to OA) and to overlook the faster, surer, and already more heavily traveled green road of OA self-archiving.” (p. 314) |
| Antelmann (2004) | Do Open-Access Articles Have a Greater Research Impact? | Open access articles have a higher research impact than not freely available articles. “This study indicates that, across a variety of disciplines, open-access articles have a greater research impact than articles that are not freely available.” (p. 379) |
When it comes the open access of research publications, the argument is often less researcher-centric. Cribb and Sari (2010) make the case for the open access to scientific knowledge as a human right (see table 4). According to them, there is a gap between the creation and the sharing of knowledge: While scientific knowledge doubles every 5 years, the access to this knowledge remains limited—leaving parts of the world in the dark: “As humanity progresses through the 21st century (…) many scholars point to the emergence of a disturbing trend: the world is dividing into those with ready access to knowledge and its fruit, and those without.” (ibid., p. 3). For them, free access to knowledge is a necessity for human development. In a study on open access in library and information science, Rufai et al. (2011) take the same line. They assume that countries “falling in the low-income economic zones have to come on open access canvas” (ibid., 2011, p. 225). In times of financial crises, open journal systems and consequently equal access to knowledge could be an appropriate solution. Additionally, Phelps et al. (2012) regard open access to research publications as a catalyst for development, whereas limited access to a small subset of people with subscription is a hindrance to development. Consistently, they define open access as “the widest possible dissemination of information” (ibid., p. 1).
Apart from the developmental justification, Phelps et al. (2012) mention another, quite common, logic for open access to research publications: “It is argued (…) that research funded by tax-payers should be made available to the public free of charge so that the tax-payer does not in effect pay twice for the research (…)” (ibid., p.1). ‘Paying twice for research’ refers to the fact that citizens do not only indirectly finance government-funded research but also the subsequent acquisition of publications from public libraries.
Carroll (2011) also criticizes the inefficiency of traditional, subscription-financed scientific journals in times of growth in digital technologies and networks. He argues that prices should have dropped considerably in the light of the Internet—instead they have increased drastically. He further argues that the open access model would shift the balance of power in journal publishing and greatly enhance the efficiency and efficacy of scientific communication (ibid., p. 1). By shifting the financing away from subscriptions, the open access model re-aligns copyright and enables broad reuse of publications while at the same time assuring authors and publishers that they receive credit for their effort (e.g. through open licensing).
Pragmatic School: Making Research More Efficient
Advocates of the pragmatic school regard Open Science as a method to make research and knowledge dissemination more efficient. It thereby considers science as a process that can be optimized by, for instance, modularizing the process of knowledge creation, opening the scientific value chain, including external knowledge and allowing collaboration through online tools. The notion of ‘open’ follows in this regard very much the disclosed production process known from open innovation concepts (see table 5).
| Author (Year) Type of Publication | Title | Content |
| Tacke (2008) Proceedings | Open science 2.0: How research and education can benefit from open innovation and web 2.0 | Complex situations can be better judged by the collective wisdom of the crowds. “However, several critics emphasize that one person can never possess enough knowledge in order to judge complex situations expediently, and that it may more appropriate to use the collective wisdom of crowds.” (p. 37) |
| Haeussler (2011) Journal Article | Information-sharing, social capital, open science | Scientists expect a benefit from sharing information. “My study showed that factors related to social capital influence the impact of the competitive value of the requested information on a scientist’s decision to share or withhold information.” (p. 117) |
| Neylon & Wu (2009) Symposium Workshop | Open science: tools, approaches, and implications | Open science tools need to fit to the scientific practice of researchers. “Tools whether they be social networking sites, electronic laboratory notebooks, or controlled vocabularies, must be built to help scientists do what they are already doing, not what the tool designer feels they should be doing” (p. 543) |
| Nielsen (2012) Monograph | Reinventing Discovery: The New Era of Networked Science | “We need to imagine a world where the construction of the scientific information commons has come to fruition. This is a world where all scientific knowledge has been made available online, and is expressed in a way that can be understood by computers” (ibid., p. 111) |
| Weiss (2005) | The Power of Collective Intelligence | Participation in collective knowledge-creation depends on the tools and services available. “With ever more sophisticated APIs and Web services being shared, attracting a critical mass of developers to build tools on those services, and a critical mass of users contributing to the services’ value by aggregating shared knowledge and content, we have the makings of a truly collaborative, self-organizing platform.” (p. 4) |
| Arazy et al. (2006) | Wisdom of the Crowds: Decentralized Knowledge Construction in Wikipedia | Participation in the co-creation of knowledge depends on the entry barriers “To entice participation, organizations using wikis should strive to eliminate barriers (e.g. allow users to post anonymously) and provide incentives for contributions.” |
| Gowers & Nielsen (2009) | Massively Collaborative Mathematics | Natural sciences can profit from collaboration of researchers. “But open sharing of experimental data does at least allow open data analysis. The widespread adoption of such open-source techniques will require significant cultural changes in science, as well as the development of new online tools. We believe that this will lead to the widespread use of mass collaboration in many fields of science, and that mass collaboration will extend the limits of human problem-solving ability.” (p. 881) |
Tacke (2010) for instance builds upon the connection between open innovation and Open Science. Similar to open innovation, the author applies the outside-in (including external knowledge to the production process) and inside-out (spillovers from the formerly closed production process) principles to science. He regards Web 2.0 in this regard as a fertile ground for practicing collaborative research (ibid., p. 41) and emphasizes the ‘wisdom of the crowds’ as a necessity in solving today’s scientific problems: “Taking a closer look at science reveals a similar situation: problems have become more complex and often require a joint effort in order to find a solution” (ibid., p. 37).
Tacke refers to Hunter and Leahey (2008) who examined trends in collaboration over a 70 years period. They found out that between 1935 and 1940 only 11 % of the observed articles were co-authored, whereas between 2000 and 2005 almost 50 % were coauthored—a significant increase that according to Tacke issues from the increasing complexity of research problems over time; research problems that apparently can only be solved through multi-expert consideration. Indeed, Bozeman and Corley (2004) found out in an empirical study on researcher collaboration that some of the most frequent reasons for collaborative research are access to expertise, aggregation of different kinds of knowledge, and productivity. Apart from the assumed increasing complexity of today’s research problems and the researcher’s pursuit of productivity, Tacke also points out the technical progress that enables and fosters collaboration in the first place. The Web 2.0 allows virtually anyone to participate in the process of knowledge creation (ibid., p. 4). It is thus tenable to consider, besides the strive for productivity and the increasing complexity of research process, also the emerging communication and collaboration technology as a solid reason for collaborative research.
Nielsen (2012) argues accordingly. He proceeds from the assumption that openness indicates a pivotal shift in the scientific practice in the near future—namely from closed to collaborative. Through reference to numerous examples of collective intelligence, such as the Polymath Project (in which Tim Gower posted a mathematical problem on his blog that was then solved by a few experts) or the Galaxy Zoo Project (an online astronomy project which amateurs can join to assist morphological classification), he emphasizes the crucial role of online tools in this development: “Superficially, the idea that online tools can make us collectively smarter contradicts the idea, currently fashionable in some circles, that the Internet is reducing our intelligence” (ibid., p. 26).
Nielsen’s presentation of examples for collaborative knowledge discoveries permits conjecture on the wide variety of collaborative research when it comes to scale and quality—be it a rather-small scale expert collaboration as in the Polymath project or large-scale amateur collaboration as in the Galaxy Zoo project. Nielsen also points towards the importance of Open Data (ibid., p. 101) and promotes comprehensive scientific commons: “We need to imagine a world where the construction of the scientific information commons has come to fruition. This is a world where all scientific knowledge has been made available online, and is expressed in a way that can be understood by computers” (ibid., p. 111). It becomes obvious that Nielsen’s vision of Open Science is based on vesting conditions like the enhanced use of online platforms, the inclusion of non-experts in the discovery process and, not least, the willingness to share on the part of scientists; all of which show that Nielsen’s notion of collective research is also bound to numerous profound changes in the scientific practice—not to mention the technological ability to understand all formats of knowledge by computers.
Haeussler (2011) addresses the sharing behaviour of researchers in an empirical study among scientists. She uses arguments from social capital theory in order to explain why individuals share information even at (temporary) personal cost. Her notion of Open Science is thereby strongly bound to the free sharing of information (similar to one of Nielsen’s core requirements for Open Science). One of Haeussler’s results concerns the competitive value of information. She concludes: “My study showed that factors related to social capital influence the impact of the competitive value of the requested information on a scientist’s decision to share or withhold information.” (ibid., p. 117). If academic scientists expect the inquirer to be able to return the favor, they are much more likely to share information. Haeussler’s study shows that the scientist’s sharing behaviour is not altruistic per se —which is often taken for granted in texts on Open Science. Instead, it is rather built on an, even non-monetary, system of return. The findings raise the question as to how the sharing of information and thus, at least according to Nielsen and Haeussler, a basic requirement for Open Science could be expedited. It implies that a change in scientific practice comes with fundamental changes in the culture of science ; in this case the incentives to share information.
Neylon and Wu (2009), in a general text on the requirements for Open Science, elaborate more on Web 2.0 tools that facilitate and accelerate scientific discovery. According to them, tools “whether they be social networking sites, electronic laboratory notebooks, or controlled vocabularies, must be built to help scientists do what they are already doing, not what the tool designer feels they should be doing” (ibid., p. 543). The authors thereby regard the implementation of Web 2.0 tools in close relation to the existing scientific practice. Following this, scientific tools can only foster scientific discovery if they tie in with the research practice. The most obvious target, according to the authors, is in this regard ‘’“tools that make it easier to capture the research record so that it can be incorporated into and linked from papers”’‘(ibid., p. 543). Unfortunately, the authors do not further elaborate on how potential tools could be integrated in the researchers’ work flows. Nonetheless, they take a new point of view when it comes to the role of Web 2.0 tools and the necessity to integrate these into an existing research practice. In this regard, they differ from what we subsume as the infrastructure school.
The authors mentioned in this chapter reveal visionary perspectives on scientific practice in the age of Web 2.0. Nonetheless, we assume that further research must focus on the structural requirements of Open Science, the potential incentives for scientists to share information, or the potential inclusion of software tools in the existing practice. In other words: The assumed coherence in regard to Open Science still lacks empirical research.
Infrastructure School: Architecture Matters Most
The infrastructure school is concerned with the technical infrastructure that enables emerging research practices on the Internet, for the most part software tools and applications, as well as computing networks. In a nutshell, the infrastructure school regards Open Science as a technological challenge (see table 6). Literature on this matter is therefore often practice-oriented and case-specific; it focuses on the technological requirements that facilitate particular research practices (e.g. the Open Science Grid).
| Author (Year) Type of Publication | Title | Content |
| Altunay et all. (2011) Article | A Science Driven Production Cyberinfrastructure—the Open Science Grid | Science grid can be used for high-throughput research projects. “This article describes the Open Science Grid, a large distributed computational infrastructure in the United States which supports many different high-troughput scientific applications (…) to form multi-domain integrated distributed systems for science.” ( p. 201) |
| De Roure et al. (2010) Conference Paper | Towards open science: the myExperiment approach | “myExperiment is the first repository of methods which majors on the social dimension, and we have demonstrated that an online community and workflow collection has been established and is now growing around it.” (p. 2350) |
| Foster (2003) Journal Article | The grid: A new infrastructure for 21st century science | Computation is a major challenge for scientific collaboration in future. “Driven by increasingly complex problems and by advances in understanding and technique, and powered by the emergence of the Internet (…), today’s science is as much based on computation, data analysis, and collaboration as on the efforts of individual experimentalists and theorists.” (p. 52) |
| De Roure et al. (2003) Book Chapter | The Semantic Grid: A Future e-Science Infrastructure | Knowledge layer services are necessary for seamlessly automatiing a significant range of actions “While there are still many open problems concerned with managing massively distributed computations in an efficient manner and in accessing and sharing information from heterogenous sources (…), we believe the full potential of Grid computing can only be realised by fully exploiting the functionality and capabilities provided by knowledge layer services.” (p. 432) |
| Hey & Trefethen (2005) Article | Cyberinfrastructure for e-Science | Service-oriented science has the potential to increase individual and collective scientific productivity by making powerful information tools available to all, and thus enabling the widespread automation of data analysis and computation “Although there is currently much focus in the Grid community on the lowlevel middleware, there are substantial research challenges for computer scientists to develop high-level intelligent middleware services that genuinely support the needs of scientists and allow them to routinely construct secure VOs and manage the veritable deluge of scientific data that will be generated in the next few years.” (p. 820) |
In 2003, Nentwich (2003, p. 1) coined the term cyberscience to describe the trend of applying information and communication technologies to scientific research—a development that has prospered since then. The authors locate cyberscience in a Web 2.0 context, alluding not only to the technical progress that fosters collaboration and interaction among scientists, but also to a cultural change similar to the open source development. Most Open Science practices described in the previously discussed schools have to be very much understood as a part of an interplay between individuals and the tools at hand. The technical infrastructure is in this regard a cyclic element for almost all identified schools in this chapter; imagine Open Data without online data repositories or collaborative writing without web-based real-time editors. In one way or another it is the new technological possibilities that change established scientific practices or even constitute new ones, as in the case of altmetrics or scientific blogging.
Still, we decided to include the infrastructure school as a separate and superordinate school of thought due to discernible infrastructure trends in the context of Open Science; trends that in our eyes enable research on a different scale. We will therefore not list the multitude of Open Science projects and their technological infrastructure but instead dwell on two infrastructure trends and selected examples. It has to be said that these trends are not mutually exclusive but often interwoven. The trends are:
- Distributed computing: Using the computing power of many users for research
- Social and collaboration networks for scientists: Enabling researcher interaction and collaboration
Distributed Computing
A striking example for distributed computing in science is the Open Science Grid, ‘’“a large distributed computational infrastructure in the United States, which supports many different high-throughput scientific applications (…) to form multi-domain integrated distributed systems for science.”’’(Altunay et al. 2011, p. 201). Put simply, the Open Science Grid enables large-scale, data-intensive research projects by connecting multiple computers to a high-performance computer network. Autonomous computers are interconnected in order to achieve high-throughput research goals. The Open Science Grid provides a collaborative research environment for communities of scientists and researchers to work together on distributed computing problems (ibid., p. 202).
It is thus not completely accurate to confine the Open Science Grid to its computational power alone as it also provides access to storage resources, offers a software stack, and uses common operational services. Nonetheless, its core strength resides in the computational power of many single computers, allowing scientists to realize data-intensive research projects, high throughput processing and shared storage. Typical projects that use the Open Science Grid are therefore CPU-intensive, comprise a large number of independent jobs, demand a significant amount of database-access, and/or implicate large input and output data from remote servers.
Foster encapsulates the increasing importance of grids as an essential computing infrastructure: “‘’Driven by increasingly complex problems and by advances in understanding and technique, and powered by the emergence of the Internet (…), today’s science is as much based on computation, data analysis, and collaboration as on the efforts of individual experimentalists and theorists.”’’(2003, p. 52). Foster (ibid.) further emphasizes the potential to enable large-scale sharing of resources within distributed, often loosely coordinated and virtual groups—an idea that according to the author is not all new. He refers to a case from 1968, when designers of the Multics operating system envisioned a computer facility operating as a utility (ibid, p. 52). What is new though, according to Foster, is the performance of such network utilities in the light of technological progress (ibid., p. 53).
Distributed computing allows scientists to realize research almost independently from the individual computing resources. It is thereby an opportunity to untie a researcher from locally available resources by providing a highly efficient computer network. Considering the importance of big data, scientific computing will be an essential research infrastructure in the near future. One could say that the objective of scientific computing is the increase of performance by interconnecting many autonomous and dispersed computers.
Social and Collaboration Networks
A second, more researcher-centric, infrastructure trend focuses on platforms that foster interaction between locally dispersed individuals and allow collaboration by implementing Web 2.0 tools. Drawing on the example of myExperiment, De Roure et al. (2008) propose four key capabilities of what they consider a Social Virtual Research Environment (SVRE):
- According to the authors, a SVRE should firstly facilitate the management and sharing of research objects. These can be any digital commodities that are used and reused by researchers (e.g. methods and data).
- Secondly, it should have incentives for researchers to make their research objects available.
- Thirdly, the environment should be open and extensible—meaning that software, tools and services can be easily integrated.
- Fourthly, it should provide a platform to action research. Actioning research is, in the authors’ understanding, what makes a platform an actual research environment. Research objects are in this regard not just stored and exchanged but they are used in the conduct of research (De Roure 2008, p. 182).
This depiction of a SVRE does of course not exclude mass computation (the third capability in fact endorses the integration of additional services)—it does, however, clearly focus on the interaction and collaboration between researchers. Furthermore, it becomes apparent that the authors’ notion of ‘virtual social research’ involves a multitude of additional tools and services enabling collaborative research. It implies (directly or indirectly) the existence of integrated large-scale data repositories that allow researchers to make their data publicly available in the first place.
Nentwich and König (2012, p. 42), who are also featured in this book, point towards other social networks for scientists, such as ResearchGate, Mendeley, Nature Networks, Vivo, or Academia.edu. The authors state that present academic social networks are principally functional for scientists and do not (yet) feature a convergence towards one provider. They further point towards the use of multi-purpose social networks (such as Facebook, LinkedIN, or Xing) among scientists. These are used for thematic expert groups (not only scientists), self-marketing, or job exchange. In the chapter “Academia Goes Facebook?: The Potential of Social Network Sites in the Scholarly Realm”, the authors elaborate more on the role of social networks for scientists—including tools for scientific collaboration such as collaborative writing environments.
Measurement School: Finding Alternative Measurements for Scientific Output
The measurement school is concerned with alternative standards to ascertain scientific impact. Inarguably, the impact factor, which measures the average number of citations to an article in a journal, has a decisive influence on a researcher’s reputation and thereby his or her funding and career opportunities. It is therefore hardly surprising that a discourse about Open Science and how science will be done in the future is accompanied by the crucial question as to how scientific impact can be measured in the digital age.
Advocates of the Open Science measurement school express the following concerns about the current impact factor:
- The peer review is time-consuming. (McVeigh 2004; Priem & Costello, 2010)
- The impact is linked to a journal rather than directly to an article. (McVeigh 2004)
- New publishing formats (e.g. online open access journals, blogs) are seldom in a journal format to which an impact factor can be assigned to (Weller & Puschmann 2012; Priem et al. 2012; Yeong & Abdullah 2012)
Accordingly, this school argues the case for an alternative and faster impact measurement that includes other forms of publication and the social web coverage of a scientific contribution. The general credo is: As the scholarly workflow is migrates increasingly to the web, formerly hidden uses like reading, bookmarking, sharing, discussing, and rating are leaving traces online and offer a new basis by which to measure scientific impact. The umbrella term for these new impact measurements is altmetrics (see table 7).
| Author (Year) | Title | Content |
| Priem & Light Costello (2010) Proceedings | How and why scholars cite on twitter | Tweets can be used as an alternative basis to measure scientific impact. ”Twitter citations are much faster than traditional citations, with 40% occurring within one week of the cited resource’s publication. Finally, while Twitter citations are different from traditional citations, our participants suggest that they still represent and transmit scholarly impact.” |
| Weller & Puschmann (2011) Poster | Twitter for Scientific Communication: How Can Citations/References be Identified and Measured? | Scientific tweets can be identified in numerous ways |
| Priem et al. (2012) Proceedings | Uncovering impacts: CitedIn and total-impact, two new tools for gethering altmetrics | CitedIn and total-impact are tools that can measure scientific impact. “CitedIn and total-impact are two tools in early development that aim to gather altmetrics. A test of these tools using a real-life dataset shows that they work, and that there is a meaningful amount of altmetrics data available” |
| McVeigh (2012) News paper article | Twitter, peer review and altmetrics: the future of research impact assessment | “So why is a revolution needed? Because long before the tools even existed to do anything about it, many in the research community have bemoaned the stranglehold the impact factor of a research paper has held over research funding, careers and reputations.” |
| Priem & Hemminger (2012) Journal article | Decoupling the scholarly journal | “This tight coupling [of the journal system] makes it difficult to change any one aspect of the system, choking out innovation.” |
| Yeong & Abdullah (2012) Position paper | Altmetrics: the right step forward | Altmetrics are an alternative metric for analysing and informing scholarship about impact. “Altmetrics rely on a wider set of measures [than webometrics] (…) are focused on the creation and study of new metrics based on the social web for analysing and informing scholarship.” |
| Björneborn & Ingwerson (2001) Journal article | Perspectives of webometrics | The lack of metadata attached to web documents and links and the lack of search engines exploiting metadata affects filtering options, and thus knowledge discovery options, whereas field codes in traditional databases support KDD (Knowledge Discovery in Databases). “As stated above, the feasibility of using bibliometric methods on the Web is highly affected by the distributed, diverse and dynamical nature of the Web and by the deficiencies of search engines. That is the reason that so far the Web Impact Factor investigations based on secondary data from search engines cannot be carried out.” (p. 78) |
Yeong and Abdullah (2012) state that altmetrics differ from webometrics which are, as the authors argue, relatively slow, unstructured, and closed. Altmetrics instead rely upon a wider set of measures that includes tweets, blogs, discussions, and bookmarks (e.g. mendeley.com). Altmetrics measure different forms of significance and usage patterns by looking not just at the end publication, but also the process of research and collaboration (ibid., p. 2). Unfortunately, the authors do not further outline how a scientific process instead of a product could be evaluated. A possibility could be to measure the impact of emerging formats of research documentation in the social web (e.g. scientific blogs) or datasets (e.g. Open Data).
As a possible basis for altmetrics, Priem et al. (2011, p. 1) mention web pages, blogs, and downloads, but also social media like Twitter, or social reference managers like CiteULike, Mendeley, and Zotero. As a result of a case study with 214 articles, they present the two open-source online tools, CitedIn and Total Impact, as potential alternatives to measure scientific impact as they are based on a meaningful amount of data from more diverse academic publications. At the same time, they emphasize that there is still a need for research regarding the comparability of altmetrics, which is difficult due to the high dimensionality of altmetrics data.
While many authors already recognize the need for new metrics in the digital age and a more structured and rapid alternative to webometrics (Young et al. 2012), research on this matter is still in its infancy. There is scarcely any research on the comparability of altmetrics and virtually no research on their potential manipulations and network effects. Furthermore, altmetrics are not yet broadly applied in the scientific community, raising the question as to what hinders their broad implementation. A possible reason is the tight coupling of the existing journal system and its essential functions of archiving, registration, dissemination, and certification of scholarly knowledge (Priem & Hemminger 2012). All the more, it appears that future research should also focus on the overall process of science, its transformative powers, and, likewise, constraints.
Discussion
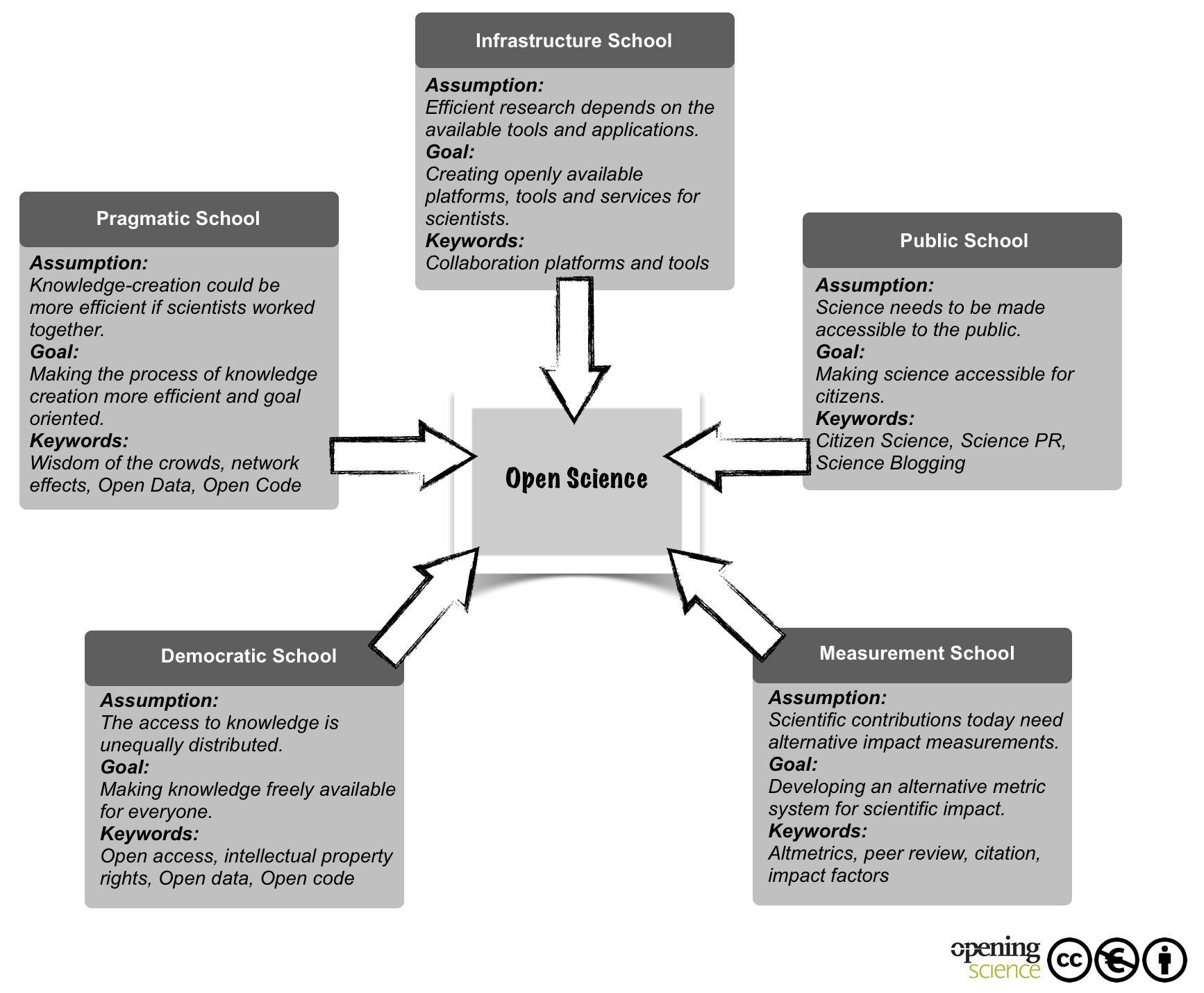
This chapter showed that “Open Science” is an umbrella term that encompasses almost any dispute about the future of knowledge creation and dissemination, a term that evokes quite different understandings depending on the viewpoint of its respective advocates and leads to many quarrels under the same flag—yet with varying inducements and targets. Even though the chapter implies a certain lack of conceptual clarity in the term Open Science, we do not promote a precisely defined concept. On the contrary, we assume that doing so could prevent fertile discussions from the very beginning. We therefore aimed at offering an overview of the leading discourses by suggesting five (more or less) distinct schools of thought, and their core aims and argumentations. We suggest that this classification can be a starting point for structuring the overall discourse and locating its common catchphrases and argumentations. In this respect the mindmap graphic below attempts to arrange the most common keywords in the Open Science discourse according to the aforegoing described schools.
Although Open Science covers in the broadest sense anything about the future of knowledge creation and dissemination, not necessarily all developments described in this chapter are novel. In fact, many demands and argumentations existed long before the dawn of the Internet and the digital age. Some would even argue that science is per definition open, since the aim of research is, after all, to publish its results, and as such to make knowledge public. Nonetheless, science certainly has experienced a new dynamic in the light of modern communication technology. Collaborative forms of research, the increasing number of co-authored scientific articles, new publication formats in the social web, the wide range of online research tools, and the emergence of open access journals all bear witness to what is entitled in this book ‘the dawn of a new era’.
Science is doubtlessly faced with enormous challenges in the coming years. New approaches to knowledge creation and dissemination go hand in hand with profound systemic changes (e.g. when it comes to scientific impact), changes in the daily practice of researchers (e.g. when it comes to new tools and methods), changes in the publishing industry (e.g. when it comes to coping with alternative publication formats), and many more. In this regard, this chapter should not only provide insight into the wide range of developments in the different Open Science schools, but also point towards the complexity of the change, the intertwinedness of the developments, and thus the necessity for holistic approaches in research on the future of research. For example: How could one argue for extensive practicing of Open Data if there is no remuneration for those who do it? How could one expect a researcher to work collaboratively online if platforms are too complicated to use? Why should a researcher invest time and effort in writing a blog if it has no impact on his or her reputation?
The entirety of the outlined developments in this chapter marks a profound change of the scientific environment. Yet even if the most prominent accompaniments of this change (be it open access, Open Data, citizen science, or collaborative research) are possibly overdue for a knowledge industry in the digital age and welcomed by most people who work in it, they still depend upon comprehensive implementation. They depend upon elaborate research policies, convenient research tools, and, not least, the participation of the researchers themselves. In many instances Open Science appears to be somewhat like the proverbial electric car—an indeed sensible but expenseful thing which would do better to be parked in the neighbor’s garage; an idea everybody agrees upon but urges others to take the first step for.
References
Altunay, M. et al., 2010. A Science Driven Production Cyberinfrastructure—the Open Science Grid. Journal of Grid Computing, 9(2), pp.201–218. doi:10.1007/s10723-010-9176-6.
Antelmann, K., 2004. Do Open Access articles have a greater research impact? College & Research Libraries, 65(5), pp.372–382.
Arazy, O., Morgan, W. & Patterson, R., 2006. Wisdom of the Crowds: Decentralized Knowledge Construction in Wikipedia. SSRN Electronic Journal. doi:10.2139/ssrn.1025624.
Auer, S. et al., 2007. DBpedia: A Nucleus for a Web of Open Data. In K. Aberer et al., eds. The Semantic Web. Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 722–735. Available at: http://www.springerlink.com/index/10.1007/978-3-540-76298-0_52.
Björneborn, L. & Ingwersen, P., 2004. Toward a basic framework for webometrics. Journal of the American Society for Information Science and Technology, 55(14), pp.1216–1227. doi:10.1002/asi.20077.
Boulton, G. et al., 2011. Science as a public enterprise: the case for open data. The Lancet, 377(9778), pp.1633–1635. doi:10.1016/S0140-6736(11)60647-8.
Bozeman, B. & Corley, E., 2004. Scientists’ collaboration strategies: implications for scientific and technical human capital. Research Policy, 33(4), pp.599–616. doi:10.1016/j.respol.2004.01.008.
Campbell, E.G. et al., 2002. Data Withholding in Academic Genetics: evidence from a national survey. JAMA, 287(4), p.473. doi:10.1001/jama.287.4.473.
Carroll, M.W., 2011. Why Full Open Access Matters. PLoS Biology, 9(11), p.e1001210. doi:10.1371/journal.pbio.1001210.
Catlin-Groves, C.L., 2012. The Citizen Science Landscape: From Volunteers to Citizen Sensors and Beyond. International Journal of Zoology, 2012, pp.1–14. doi:10.1155/2012/349630.
Cribb, J. & Sari, T., 2010. Open science: sharing knowledge in the global century, Collingwood, VIC: CSIRO Publishing.
Ebner, M. & Maurer, H., 2008. Can microblogs and weblogs change traditional scientific writing? In Proceedings of World Conference on ELearning in Corporate, Government, Healthcare, and Higher Education 2008. Las Vegas, Nevada, USA, pp. 768–776.
Ebner, M. & Maurer, H., 2009. Can Weblogs and Microblogs Change Traditional Scientific Writing? Future Internet, 1(1), pp.47–58. doi:10.3390/fi1010047.
Foster, I., 2002. The Grid: A New Infrastructure for 21st Century Science. Physics Today, 55(2), p.42. doi:10.1063/1.1461327.
Goble, C.A. & De Roure, D.C., 2007. myExperiment. In ACM Press, pp. 1–2. doi:10.1145/1273360.1273361.
Gowers, T. & Nielsen, M., 2009. Massively collaborative mathematics. Nature, 461(7266), pp.879–881. doi:10.1038/461879a.
Grand, A. et al., 2012. Open Science: A New “Trust Technology”? Science Communication, 34(5), pp.679–689. doi:10.1177/1075547012443021.
Haeussler, C., 2011. Information-sharing in academia and the industry: A comparative study. Research Policy, 40(1), pp.105–122. doi:10.1016/j.respol.2010.08.007.
Hand, E., 2010. Citizen science: People power. Nature, 466(7307), pp.685–687. doi:10.1038/466685a.
Harnad, S. et al., 2004. The Access/Impact Problem and the Green and Gold Roads to Open Access. Serials Review, 30(4), pp.310–314. doi:10.1016/j.serrev.2004.09.013.
Hey, T., 2005. Cyberinfrastructure for e-Science. Science, 308(5723), pp.817–821. doi:10.1126/science.1110410.
Hunter, L. & Leahey, E., 2008. Collaborative Research in Sociology: Trends and Contributing Factors. The American Sociologist, 39(4), pp.290 –306.
Irwin, A., 1995. Citizen science: a study of people, expertise, and sustainable development, London ; New York: Routledge.
Irwin, A., 2006. The Politics of Talk: Coming to Terms with the “New” Scientific Governance. Social Studies of Science, 36(2), pp.299–320. doi:10.1177/0306312706053350.
Löh, A. & Hinze, R., 2006. Open data types and open functions. In ACM Press, p. 133. doi:10.1145/1140335.1140352.
McVeigh, M.E., 2004. Open Access Journals in the ISI Citation Databases: Analysis of Impact Factors and Citation Patterns. Citation Study. In Thomson Scientific. Available at: http://science.thomsonreuters.com/m/pdfs/openaccesscitations2.pdf.
Miller, P., Styles, R. & Heath, T., 2008. Open data commons, a license for open data. In Proceedings of the WWW 2008 Workshop on Linked Data on the Web.
Molloy, J.C., 2011. The Open Knowledge Foundation: Open Data Means Better Science. PLoS Biology, 9(12), p.e1001195. doi:10.1371/journal.pbio.1001195.
Morris, T. & Mietchen, D., 2010. Collaborative Structuring of Knowledge by Experts and the Public. In Proceedings of the 5th Open Knowledge Conference. London, UK, pp. 29–41.
Murray-Rust, P., 2008. Open Data in Science. Serials Review, 34(1), pp.52–64. doi:10.1016/j.serrev.2008.01.001.
Nentwich, M., 2003. Cyberscience: research in the age of the internet, Vienna: Austrian Academy of Sciences Press.
Nentwich, M. & König, R., 2012. Cyberscience 2.0: research in the age of digital social networks, Frankfurt; New York: Campus Verlag.
Neylon, C. & Wu, S., 2009. Open Science: tools, approaches, and implications. Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing, pp.540–544.
Nielsen, M.A., 2012. Reinventing discovery: the new era of networked science, Princeton, N.J.: Princeton University Press.
Nowotny, H., Scott, P. & Gibbons, M., 2001. Re-thinking science: knowledge and the public in an age of uncertainty, Cambridge, UK: Polity.
Phelps, L., Fox, B.A. & Marincola, F.M., 2012. Supporting the advancement of science: open access publishing and the role of mandates. Journal of translational medicine, 10, p.13. doi:10.1186/1479-5876-10-13.
Powell, M.C. & Colin, M., 2009. Participatory Paradoxes: Facilitating Citizen Engagement in Science and Technology From the Top-Down? Bulletin of Science, Technology & Society, 29(4), pp.325–342. doi:10.1177/0270467609336308.
Priem, J. et al., 2010. altmetrics: a manifesto. altmetrics. Available at: http://altmetrics.org/manifesto/.
Priem, J. et al., 2011. Uncovering impacts : CitedIn and total-impact, two new tools for gathering altmetrics. In iConference 2012. pp. 9–11. Available at: http://jasonpriem.org/self-archived/two-altmetrics-tools.pdf.
Priem, J. & Costello, K.L., 2010. How and why scholars cite on Twitter. Proceedings of the American Society for Information Science and Technology, 47(1), pp.1–4. doi:10.1002/meet.14504701201.
Priem, J. & Hemminger, B.M., 2012. Decoupling the scholarly journal. Frontiers in Computational Neuroscience, 6. doi:10.3389/fncom.2012.00019.
Priem, J., Piwowar, H. & Hemminger, B.M., 2012. Altmetrics in the Wild: Using Social Media to Explore Scholarly Impact. In ACM Web Science Conference 2012 Workshop. Evanston, IL, USA. Available at: http://altmetrics.org/altmetrics12/priem/.
De Roure, D. et al., 2008. myExperiment: Defining the Social Virtual Research Environment. In IEEE, pp. 182–189. doi:10.1109/eScience.2008.86.
De Roure, D. & Goble, C., 2009. Software Design for Empowering Scientists. IEEE Software, 26(1), pp.88–95. doi:10.1109/MS.2009.22.
De Roure, D., Jennings, N.R. & Shadbolt, N.R., The Semantic Grid: A Future e-Science Infrastructure. In F. Berman, G. Fox, & T. Hey, eds. Wiley Series in Communications Networking & Distributed Systems. Chichester, UK: John Wiley & Sons, Ltd, pp. 437–470.
Rufai, R., Gul, S. & Shah, T.A., 2012. Open Access Journals in Library and Information Science: The Story so Far. Trends in Information Management, 7(2).
Tacke, O., 2010. Open Science 2.0: How Research and Education Can Benefit from Open Innovation and Web 2.0. In T. J. Bastiaens, U. Baumöl, & B. J. Krämer, eds. On Collective Intelligence. Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 37–48.
Tacke, O., 2012. Raus aus dem Elfenbeinturm: Open Science. olivertacke.de. Available at: http://www.olivertacke.de/2011/10/23/raus-aus-dem-elfenbeinturm-open-science/.
Vision, T.J., 2010. Open Data and the Social Contract of Scientific Publishing. BioScience, 60(5), pp.330–331. doi:10.1525/bio.2010.60.5.2.
Weiss, A., 2005. The power of collective intelligence. netWorker, 9(3), pp.16–23. doi:10.1145/1086762.1086763.
Weller, K. & Puschmann, C., 2011. Twitter for Scientific Communication: How Can Citations/References be Identified and Measured? In Proceedings of the ACM WebSci’11. Koblenz: ACM Publishers, pp. 1–4.
Weschsler, D., 1971. Concept of collective intelligence. American Psychologist, 26(10), pp.904–907.
Yeong, C.H. & Abdullah, B.J.J., 2012. Altmetrics: the right step forward. Biomedical Imaging and Intervention Journal, 8(3), pp.1–2.
Next chapter: Excellence by Nonsense: The Competition for Publications in Modern Science
Mathias Binswanger